
Python 模块
模块是包括 Python 定义和声明的文件,文件名就是模块名加上
.py后缀,模块名可以由全局变量__name__得到。Python 只有一种模块对象类型,所有模块都属于该类型,无论模块是用 Python、C 还是别的语言实现。
什么是 Python 模块
简单来说,一个 Python 模块就是一个以 .py 为后缀的文件 ,模块中能定义内容包括:变量、函数、类和可执行代码。
模块类型大致有以下 3 种:
Python 内置的模块,即标准库。
Python 带有一个标准模块库,并发布有独立的文档,名为 Python 库参考手册。有一些模块内置于解释器之中,这些操作的访问接口不是语言内核的一部分,但是已经内置于解释器了。这既是为了提高效率,也是为了给系统调用等操作系统原生访问提供接口。
第三方模块,即通过
pip install的模块。自定义模块,即用户自己编写的模块。
举个 🌰,我们写一个模块 fibo.py :
1 | # write Fibonacci series up to n |
模块导入
导入模块的方式有以下 2 种:
- import module
这是模块 完全引入 的方式。 比如 import os 会把 os 下面的所有的变量、函数、类全部引入,通过 os 可以访问模块中的变量或函数,如 os.listdir()。
当然也可以通过 import module as xx 的方式,为模块起一个别名。
- from module import func1, func2
这是模块 部分引入 的方式。按需引入需要模块中定义的函数,另一个好处是可以直接在脚本中使用复制后的变量名。
举个🌰,现在进入 Python 解释器导入该模块:
1 | >>> import fibo |
可以看到当前没有任何输出,因为导入模块的操作,只是进入到模块名 fibo 中,并不会直接进入到定义在 fibo 函数内。可以用模块名访问这些函数:
1 | >>> import fibo |
模块执行
如果需要让一个 .py 文件既当作脚本又能当作模块用,可以使用 __name__ 这个属性。只有当文件被当作脚本执行的时候, __name__ 的值才会是 '__main__',而模块导入时不会。
下面,我们改造一下上述 fibo 模块,在末尾添加一段代码:
1 | # write Fibonacci series up to n |
然后运行 Python 模块:
1 | >>> python fibo.py |
可以看到模块里的代码会被执行,就好像已导入模块一样。
模块加载机制
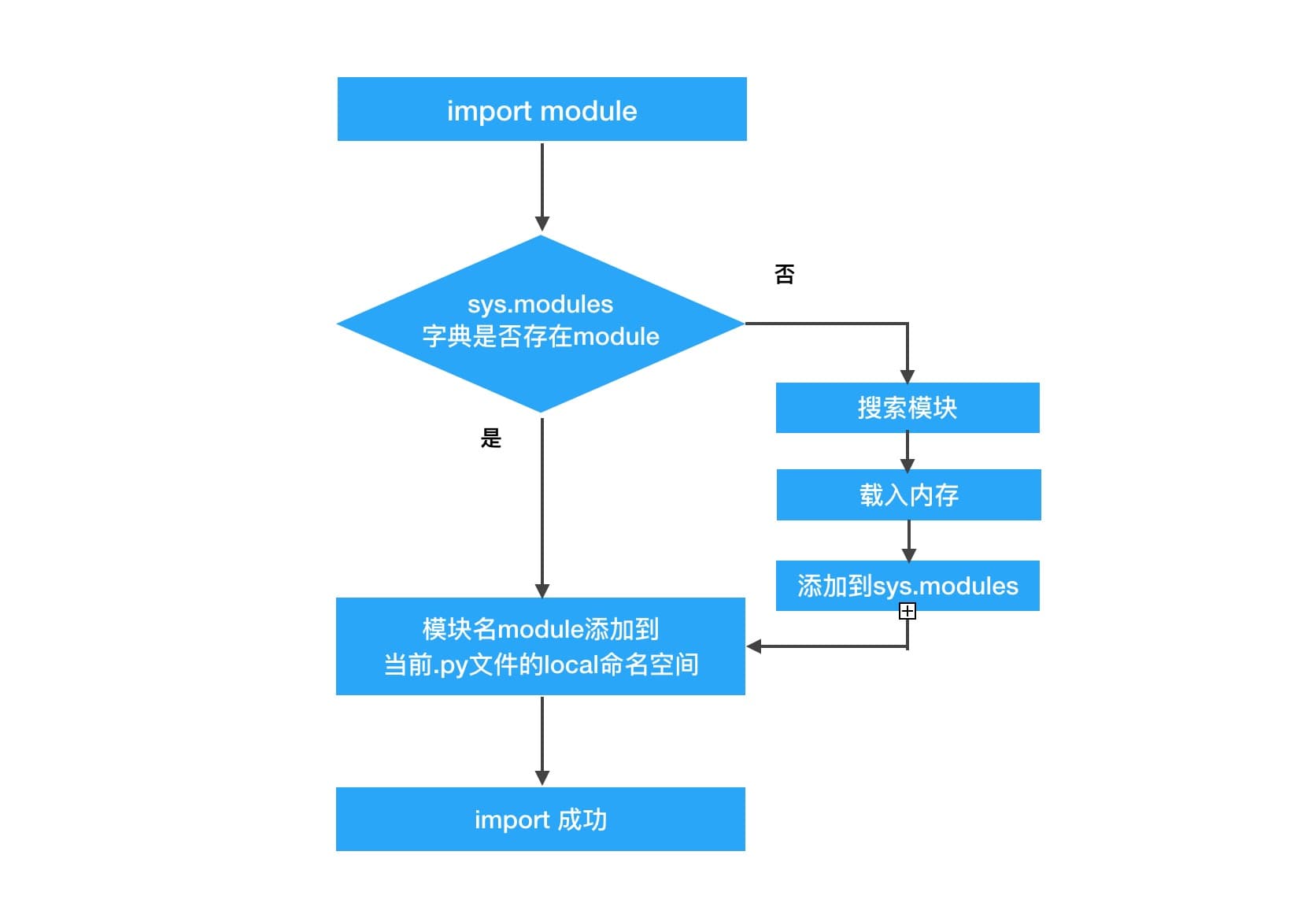
动态加载模块
但是import只能够加载固定名称模块,不能加载动态比如字符串名称模块,比如
str = ‘tools’import str
好了,现在解决了动态加载随意模块的问题了,但是距离成功还有一步之遥,在python里面,加载模块是有缓存的,意思就是说,加载tools.py之后,就算tools.py内容发生改变了,都不会重新加载,还是无法满足我们实时更新加载模块的需求。这里有个比较简单的办法,可以使得模块有需要的时候重新加载,回想之前我们说过,python加载后的模块都会保存在sys.modules里面,我们只需要在重新加载模块之前,把模块从sys.modules里面删除即可。
del sys.modules[‘tools’]import(‘tools’)
Python 包
为了帮助组织模块并提供名称层次结构,Python 还引入了包的概念。可以把包看成是文件系统中的目录,并把模块看成是目录中的文件,但请不要对这个类似做过于字面的理解,因为包和模块不是必须来自于文件系统。 与文件系统一样,包通过层次结构进行组织,在包之内除了一般的模块,还可以有子包。
简单地来说,”包“ (package) 是含有 Python 模块的文件夹,不过前提条件是这个文件夹下必须存在 __init__.py 文件。
什么是 __init__.py 文件
当文件夹下存在 __init__.py 文件时意味着该文件夹是一个包,__init__.py 文件用于组织包,管理各个模块之间的引用、控制包的导入行为。
封装包时确保每个目录都定义了一个 __init__.py 文件,举个🌰:
1 | ├── package # 顶层目录 |
组织好目录结构和代码后,便可以执行以下 import 语句:
1 | import package.subPackage1.module1 |
__init__.py 文件的目的是要包含不同运行级别的包的可选的初始化代码,导入一个包时会先导入的它的 __init__.py 文件并自动运行。
举个🌰,执行语句 import package.subPackage1.module1 时,文件 package/__init__.py 将被导入,建立 package 命名空间的内容,且 package/__init__.py 将在文件 package/subPackage1/__init__.py 导入之前导入。
一般情况下 __init__.py 文件可以为空,但是有的时候也可以在 __init__.py 中导入其他的包或模块:
1 | # package/subPackage1/__init__.py |
于是就可以通过 import package.subPackage1 代替 import package.subPackage1.module1 来导入模块了。